Unifying 3D Scene Generation and Reconstruction in Pixel Space
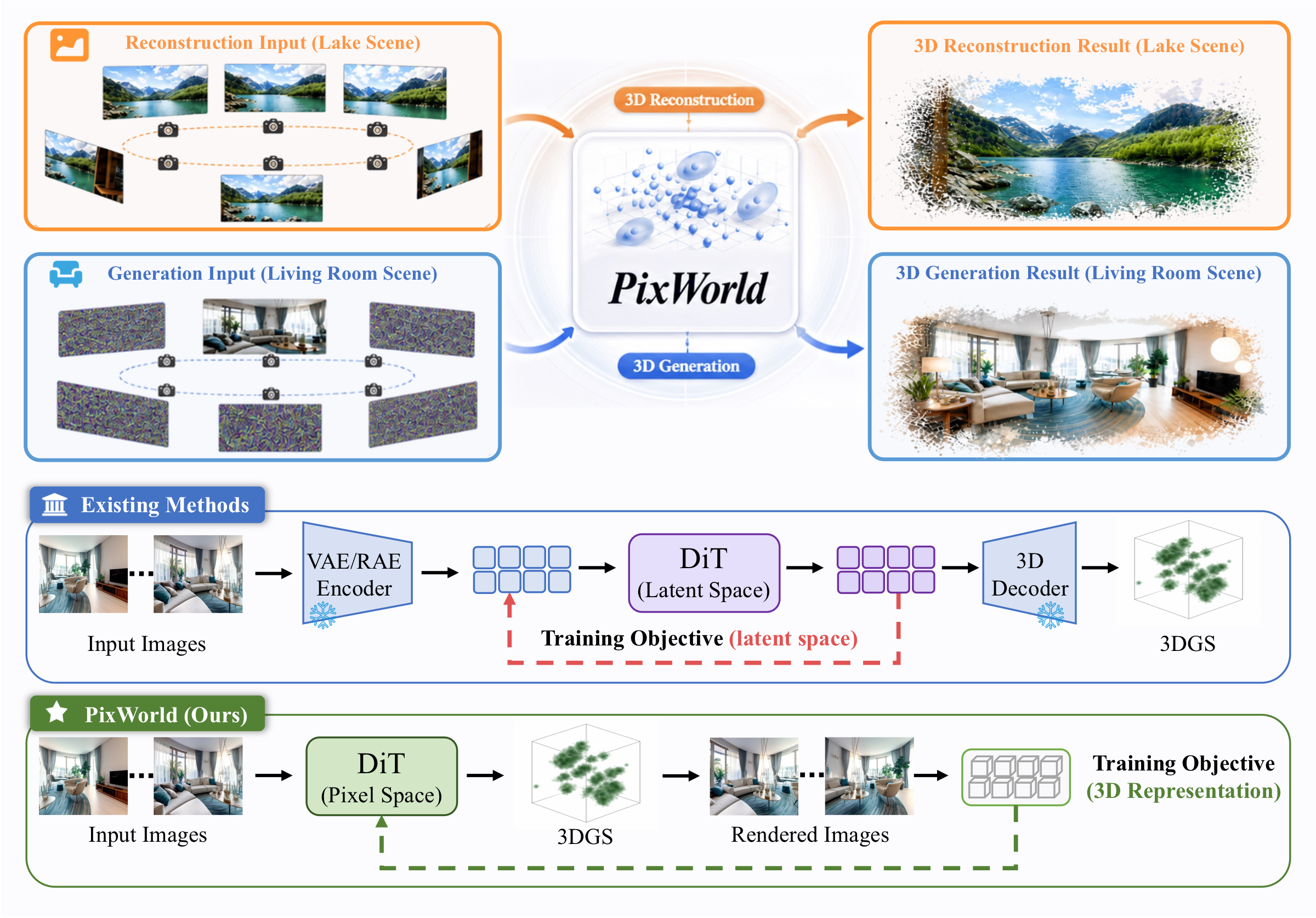
One end-to-end pixel-space diffusion model for both 3D reconstruction and generation — supervising a pixel-aligned 3D Gaussian field directly through differentiable rendering, with no VAE or RAE.
3D reconstruction, text→3D and image→3D generation from a single unified model — rendered as explorable 3D Gaussian scenes.
ReconstructionText→3DImage→3DRGB + Depth~0.6 s / scene · 4 steps
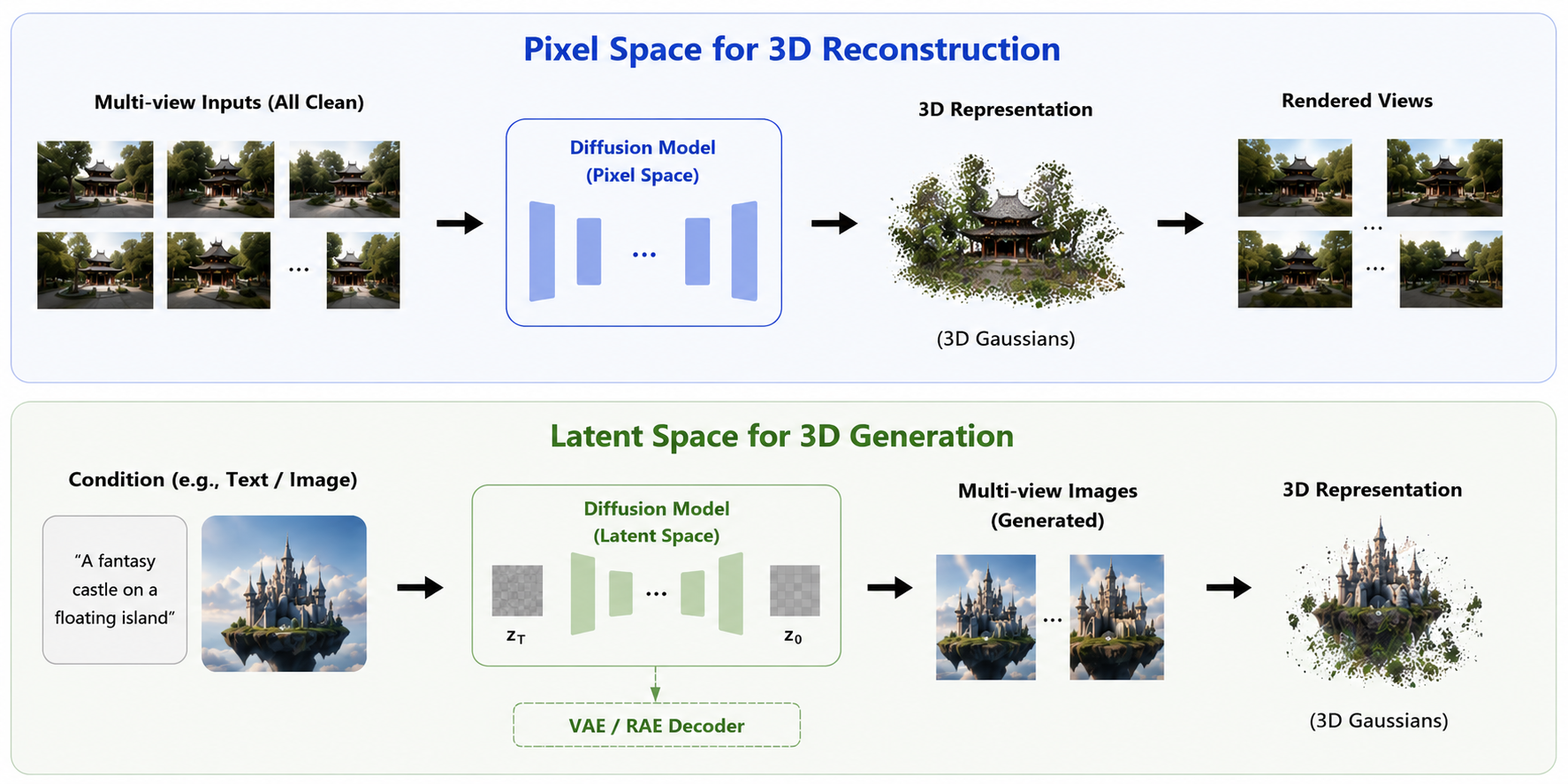
PixWorld unifies 3D scene reconstruction and generation in a single model. Unlike prior approaches that compute losses in the latent space of a VAE or RAE, PixWorld applies a flow-matching objective directly in pixel space over multi-view renderings, enabling end-to-end optimization of the underlying 3D representation — avoiding latent information loss and the cost of pretraining an autoencoder.
Abstract
One Model, in Pixel Space
3D reconstruction and generation are commonly tackled by separate paradigms: pixel-based regression for reconstruction, and latent diffusion for generation. Recent works attempt to unify them in latent space, but with notable drawbacks: the diffusion objective is defined on latent features rather than the underlying 3D representation, and both branches suffer from information loss introduced by latent encoding, while requiring a pretrained Variational Autoencoder (VAE) or Representation Autoencoder (RAE). In this paper, we reformulate these two tasks under a unified pixel-space diffusion paradigm and introduce PixWorld, a single model that jointly addresses 3D reconstruction and generation. By supervising diffusion directly on rendered images, PixWorld removes these limitations and aligns optimization with 3D scene fidelity. Beyond photometric and perceptual supervision that operates at the 2D image level and lacks 3D geometric awareness, we further introduce a geometry perception loss that aligns rendered views with their ground truth in the geometry-aware feature space of a pretrained 3D foundation model, providing 3D structural supervision. PixWorld consistently improves over prior latent-space generation methods and matches strong reconstruction methods, demonstrating the effectiveness of a unified pixel-space approach.
What's New
Key Contributions
Pixel-Space Diffusion
End-to-End, No VAE/RAE
An end-to-end pixel-space diffusion framework that supervises a pixel-aligned 3D Gaussian representation directly through multi-view differentiable rendering — eliminating the information loss and training cost of a latent autoencoder and aligning the diffusion signal with 3D scene fidelity.
Unification
Generation + Reconstruction
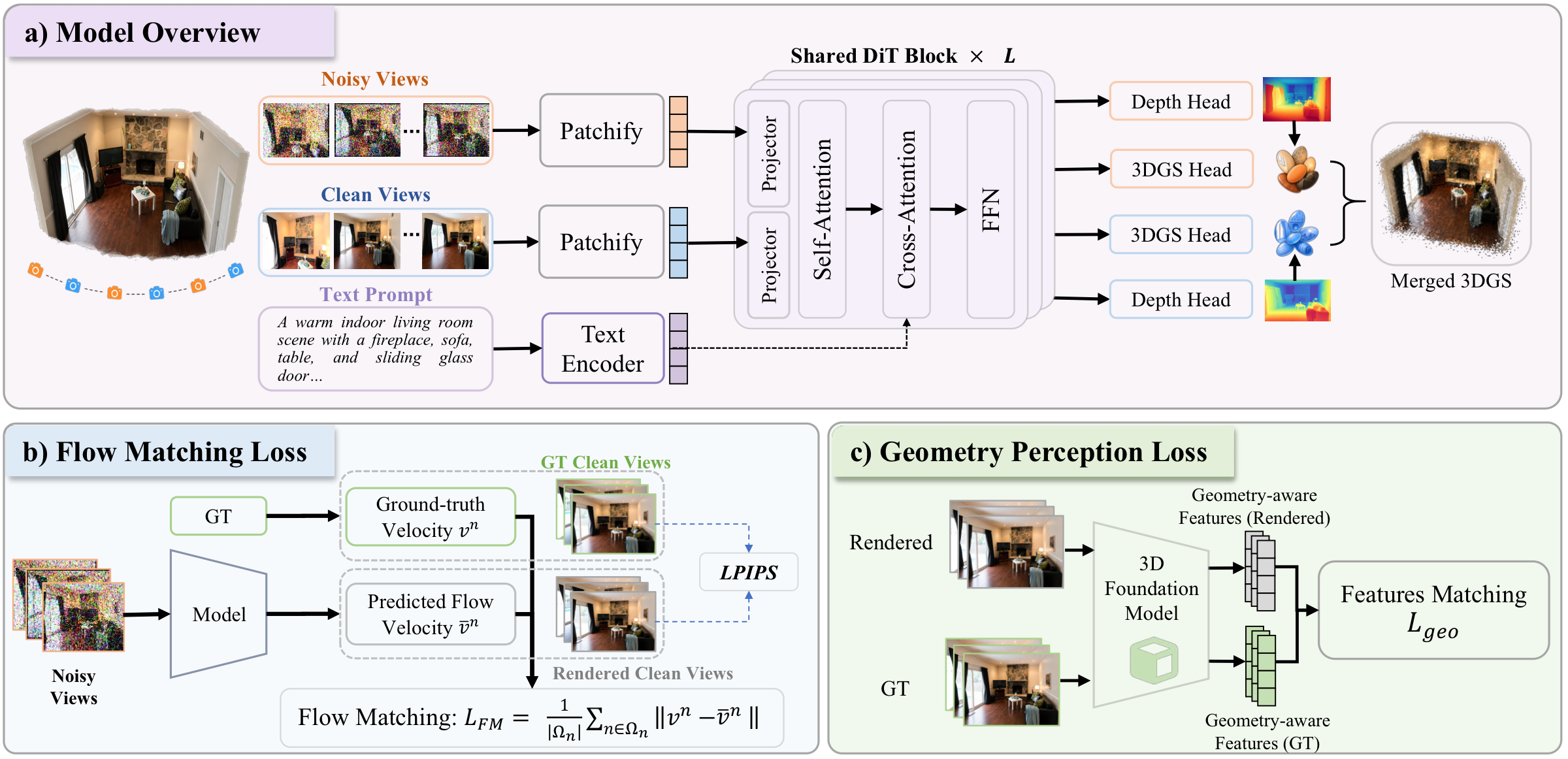
Multi-view inputs are partitioned into clean and noisy subsets: clean views drive reconstruction, while noisy ones are generated conditioned on the clean ones — both producing the same 3D Gaussian representation in a single forward pass.
Geometry Perception Loss
3D Structural Supervision
A geometry perception loss aligns rendered views with ground truth in the geometry-aware feature space of a frozen 3D foundation model (e.g. π³ / VGGT), providing 3D structural supervision beyond 2D photometric and perceptual losses.
How It Works
Method Overview
Pixel space vs. latent space. Prior latent methods compute losses in a VAE/RAE latent; PixWorld supervises diffusion directly in pixel space over rendered views, optimizing the 3D representation end-to-end for both reconstruction and generation.
(a) A unified DiT-based framework takes noisy and clean multi-view inputs, with optional text, and jointly predicts depth and 3DGS through shared transformer blocks. (b) A pixel-space flow-matching loss is imposed on rendered multi-view images to directly optimize the 3D representation. (c) A geometry perception loss enforces structural consistency by aligning rendered views with ground truth through a frozen 3D foundation model.
Method Explainer Video
Pixel-space flow matchingClean / noisy partitionTwo-stream DiTGeometry perception loss
Experiments
Results
A single PixWorld model performs both 3D reconstruction and generation, evaluated on RealEstate10K, DL3DV-10K and WorldScore.
3D Reconstruction — Novel View Synthesis
Method
RealEstate10K
DL3DV-10K
PSNR↑
SSIM↑
LPIPS↓
PSNR↑
SSIM↑
LPIPS↓
PSNR↑
SSIM↑
LPIPS↓
PSNR↑
SSIM↑
LPIPS↓
4-views
8-views
4-views
8-views
MVSplat
22.58
0.762
0.264
21.64
0.719
0.301
17.11
0.501
0.410
15.75
0.432
0.491
DepthSplat
25.16
0.832
0.194
27.77
0.872
0.154
20.38
0.719
0.320
19.26
0.692
0.360
AnySplat
20.07
0.731
0.286
20.52
0.752
0.262
20.11
0.671
0.318
20.02
0.664
0.327
YoNoSplat
25.83
0.841
0.143
28.35
0.889
0.107
23.05
0.711
0.228
21.92
0.678
0.262
PixWorld (Ours)
26.21
0.844
0.138
28.58
0.892
0.101
23.18
0.714
0.226
22.46
0.681
0.257
Best in cyan, second best underlined. Gen3R is a unified gen+recon model but only supports point-cloud reconstruction, so it is not directly comparable on NVS and is omitted here.
One model, both tasks. When all input views are clean, PixWorld reconstructs; when clean and noisy views are mixed, it generates. Blue and red frustums denote clean input views and generated views, respectively.
3D Scene Generation
Method
Novel View Synthesis
Generation Quality
Camera Control
PSNR↑
SSIM↑
LPIPS↓
I2V Subj.↑
I2V BG↑
I.Q.↑
Aes.Q.↑
AUC@30↑
AUC@15↑
AUC@5↑
RealEstate10K
LVSM
17.82
0.603
0.336
0.971
0.970
0.593
0.506
0.710
0.592
0.372
GF
15.63
0.553
0.454
0.931
0.941
0.504
0.475
0.596
0.478
0.290
Gen3C
17.26
0.624
0.391
0.951
0.956
0.561
0.524
0.648
0.514
0.334
FlashWorld
16.51
0.626
0.403
0.958
0.960
0.615
0.550
0.843
0.758
0.546
Gen3R
17.59
0.631
0.382
0.974
0.971
0.552
0.536
0.633
0.433
0.147
PixWorld (Ours)
18.88
0.702
0.325
0.979
0.978
0.623
0.556
0.869
0.798
0.614
DL3DV-10K
LVSM
14.91
0.433
0.530
0.931
0.933
0.494
0.466
0.552
0.372
0.134
GF
12.69
0.356
0.591
0.898
0.910
0.474
0.435
0.491
0.338
0.113
Gen3C
15.58
0.514
0.479
0.927
0.933
0.532
0.496
0.552
0.377
0.128
FlashWorld
15.42
0.473
0.461
0.942
0.950
0.619
0.558
0.769
0.674
0.420
Gen3R
15.75
0.503
0.495
0.944
0.942
0.547
0.530
0.593
0.398
0.117
PixWorld (Ours)
16.50
0.527
0.449
0.952
0.956
0.631
0.567
0.793
0.706
0.485
Single-image generation, averaged over First-Frame and Bidirectional trajectories.
Method
Novel View Synthesis
Generation Quality
Camera Control
PSNR↑
SSIM↑
LPIPS↓
I2V Subj.↑
I2V BG↑
I.Q.↑
Aes.Q.↑
AUC@30↑
AUC@15↑
AUC@5↑
RealEstate10K
LVSM
23.61
0.819
0.215
0.970
0.964
0.607
0.516
0.861
0.788
0.611
GF
18.27
0.647
0.353
0.925
0.939
0.507
0.464
0.630
0.473
0.223
Gen3C
20.12
0.714
0.300
0.948
0.947
0.567
0.518
0.698
0.538
0.255
FlashWorld
21.48
0.770
0.257
0.964
0.962
0.619
0.547
0.877
0.811
0.637
Gen3R
21.33
0.724
0.283
0.970
0.972
0.550
0.540
0.728
0.576
0.258
PixWorld (Ours)
23.54
0.815
0.210
0.974
0.974
0.628
0.561
0.880
0.817
0.649
DL3DV-10K
LVSM
19.18
0.589
0.343
0.915
0.917
0.533
0.502
0.740
0.609
0.374
GF
15.38
0.459
0.470
0.897
0.912
0.479
0.445
0.563
0.379
0.147
Gen3C
17.62
0.542
0.412
0.927
0.934
0.536
0.502
0.627
0.433
0.176
FlashWorld
18.27
0.562
0.359
0.938
0.948
0.600
0.558
0.802
0.714
0.514
Gen3R
18.05
0.558
0.392
0.942
0.944
0.535
0.530
0.726
0.560
0.245
PixWorld (Ours)
19.37
0.594
0.340
0.950
0.956
0.607
0.565
0.821
0.734
0.534
Two-view generation, averaged over Interpolation and Extrapolation configurations.
Method
Camera Control
Object Control
Content Align.
3D Consist.
Photo. Consist.
Style Consist.
Subj. Quality
Average
Wan-2.1
23.53
40.32
45.44
78.74
78.36
77.18
59.38
57.56
WonderJourney
84.60
37.10
35.54
80.60
79.03
62.82
66.56
63.75
LucidDreamer
88.93
41.18
75.00
90.37
90.20
48.10
58.99
70.40
FlashWorld
84.43
50.28
56.54
85.87
86.72
79.36
52.75
70.85
PixWorld (Ours)
91.08
46.25
55.27
91.39
93.84
67.11
52.36
71.04
WorldScore official static split (2000 scenes). Among the compared baselines, PixWorld reports a 71.04 average, with strong camera control, 3D and photometric consistency.
Qualitative Gallery
Comparison with baselines. The large view on top is the input; the two smaller views below are novel views generated by each method.
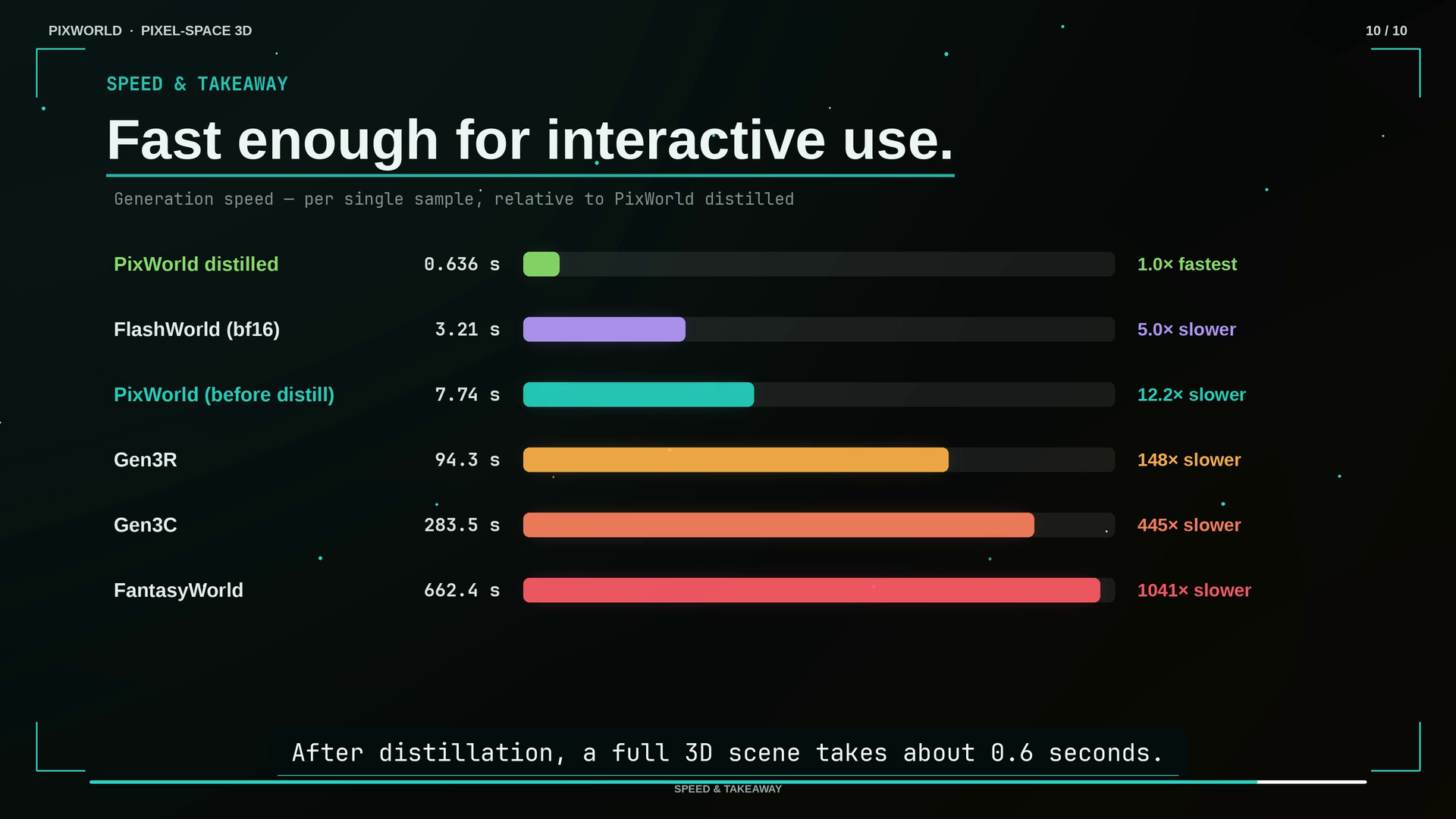
Inference speed. After distillation, the 4-step PixWorld generates a scene in ~0.6 s — up to ~1000× faster than diffusion-based world generators (per sample, relative to PixWorld distilled: FantasyWorld 1041×, Gen3C 445×, Gen3R 148×, FlashWorld 5×).
Analysis
Ablation Study
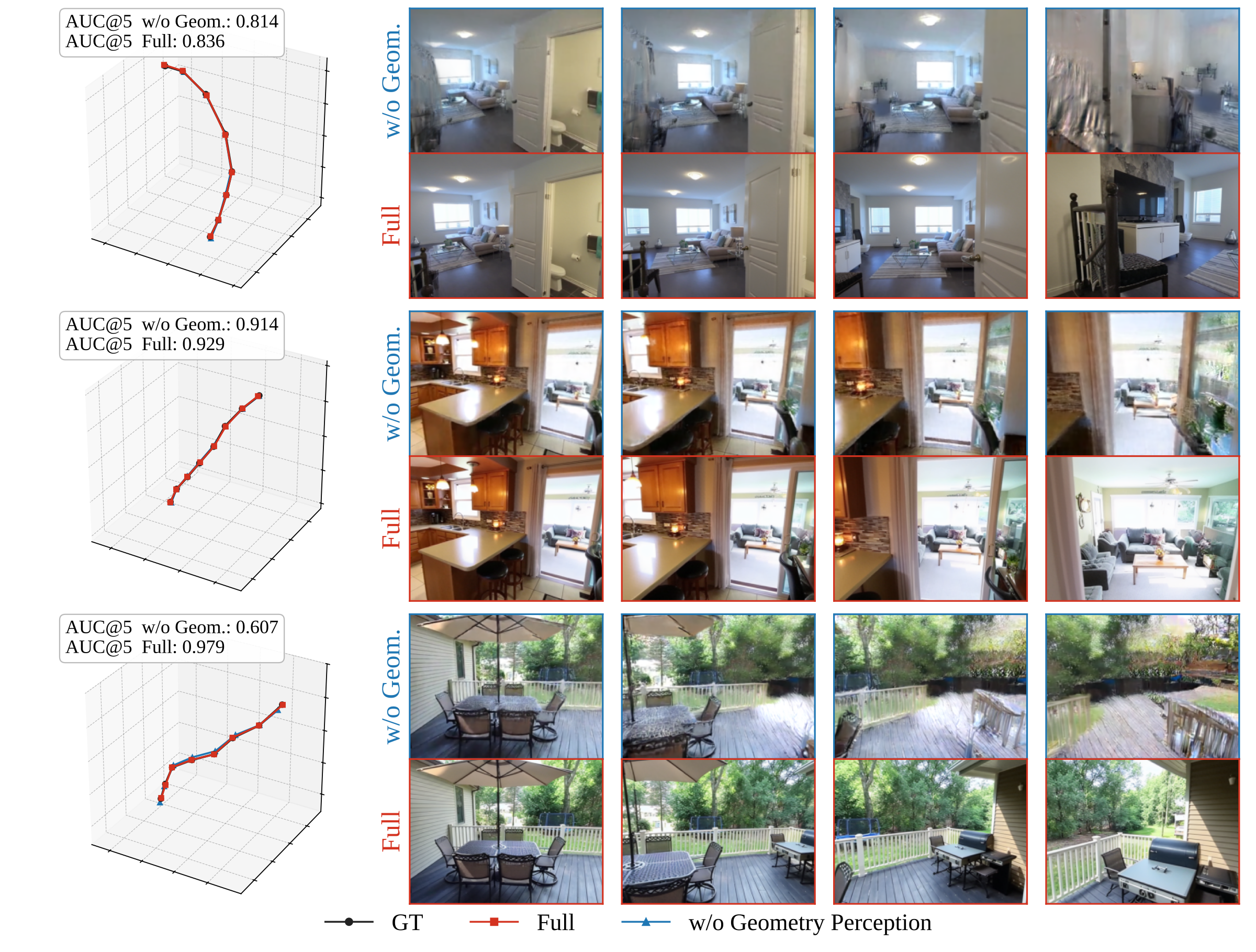
The geometry perception loss supplies the 3D structural signal that 2D objectives cannot — sharply improving fidelity and pose accuracy.
Effect of the Geometry Perception Loss (RealEstate10K, 1-view)
Variant
PSNR↑
SSIM↑
LPIPS↓
I2V Subj.↑
I2V BG↑
I.Q.↑
Aes.Q.↑
AUC@30↑
AUC@15↑
AUC@5↑
Full model
19.12
0.717
0.310
0.972
0.975
0.619
0.561
0.886
0.813
0.642
w/o Geometry Perception
17.99
0.612
0.332
0.973
0.974
0.613
0.541
0.847
0.763
0.562
Removing the geometry perception loss drops PSNR by 1.13 dB, SSIM by 0.105 and AUC@5 by 0.080 (~12.5% relative), while 2D VBench-style scores barely move — confirming the loss targets 3D structure, not 2D appearance.
Qualitative ablation. Without the geometry perception loss, frames stay individually plausible but cross-view geometry drifts; the full model preserves consistent 3D structure.
Open Source
Release Plan
We are progressively open-sourcing PixWorld. The fast distilled model and inference code come first.
Within two weeks (early July 2026): release the PixWorld-480P-4steps distilled weights and inference code.
@misc{gao2026pixworld,
title={PixWorld: Unifying 3D Scene Generation and Reconstruction in Pixel Space},
author={Sensen Gao and Zhaoqing Wang and Qihang Cao and Dongdong Yu and Changhu Wang and Jia-Wang Bian},
year={2026},
eprint={2026.XXXXX},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://github.com/SensenGao/PixWorld},
}
arXiv ID will be added once the preprint is public.