Why Multimodal RAG
From context overflow to grounded document intelligence
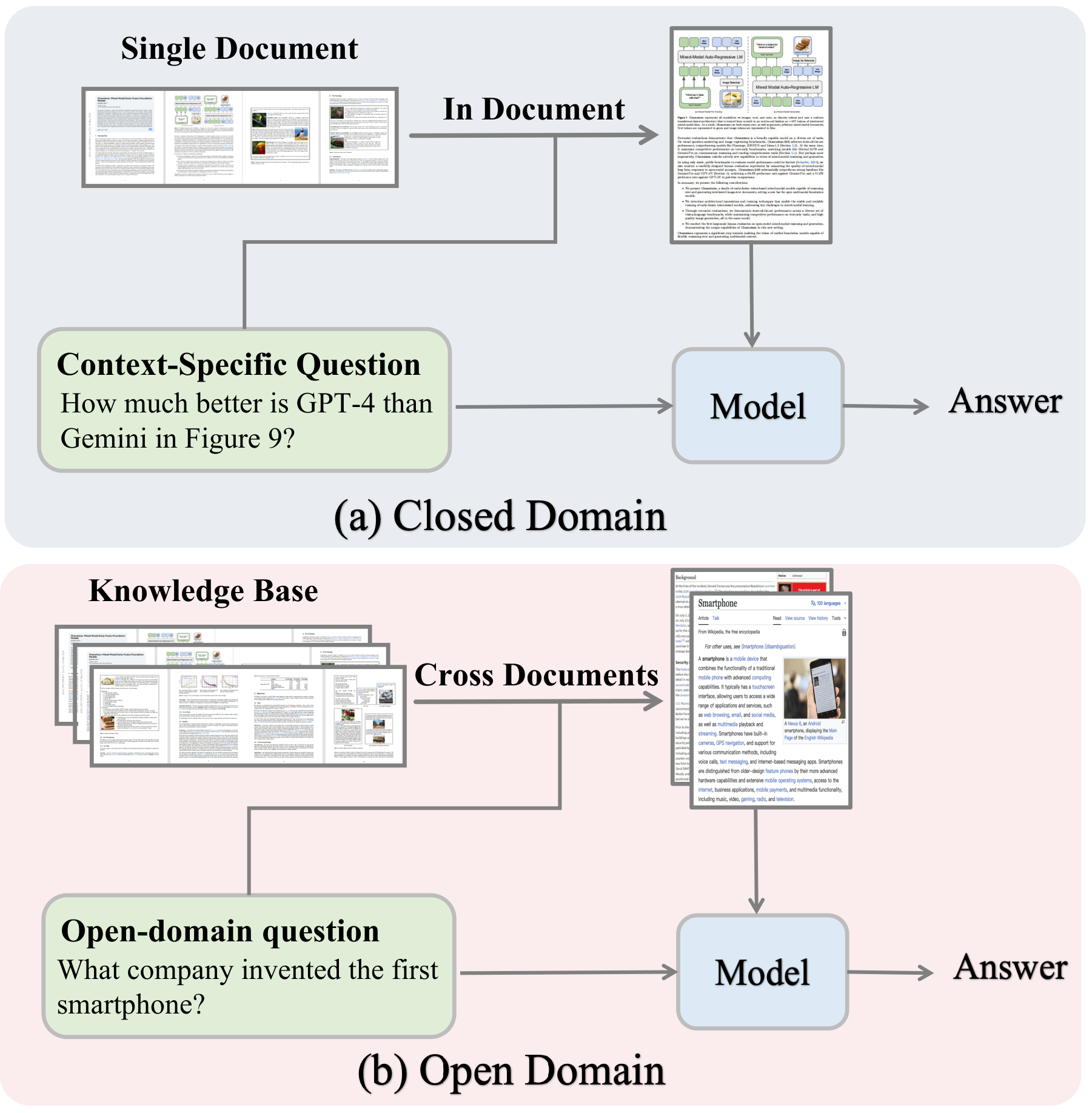
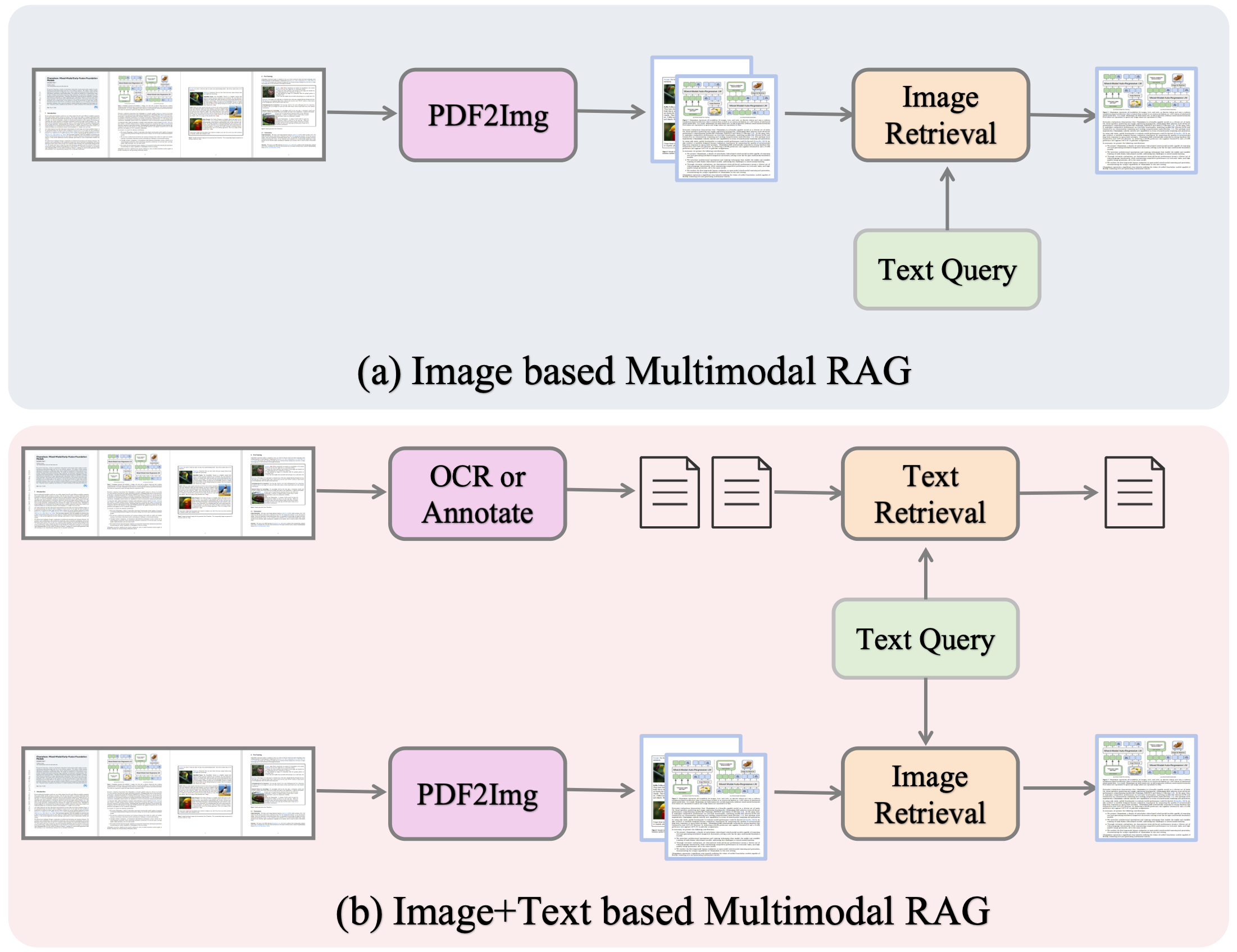
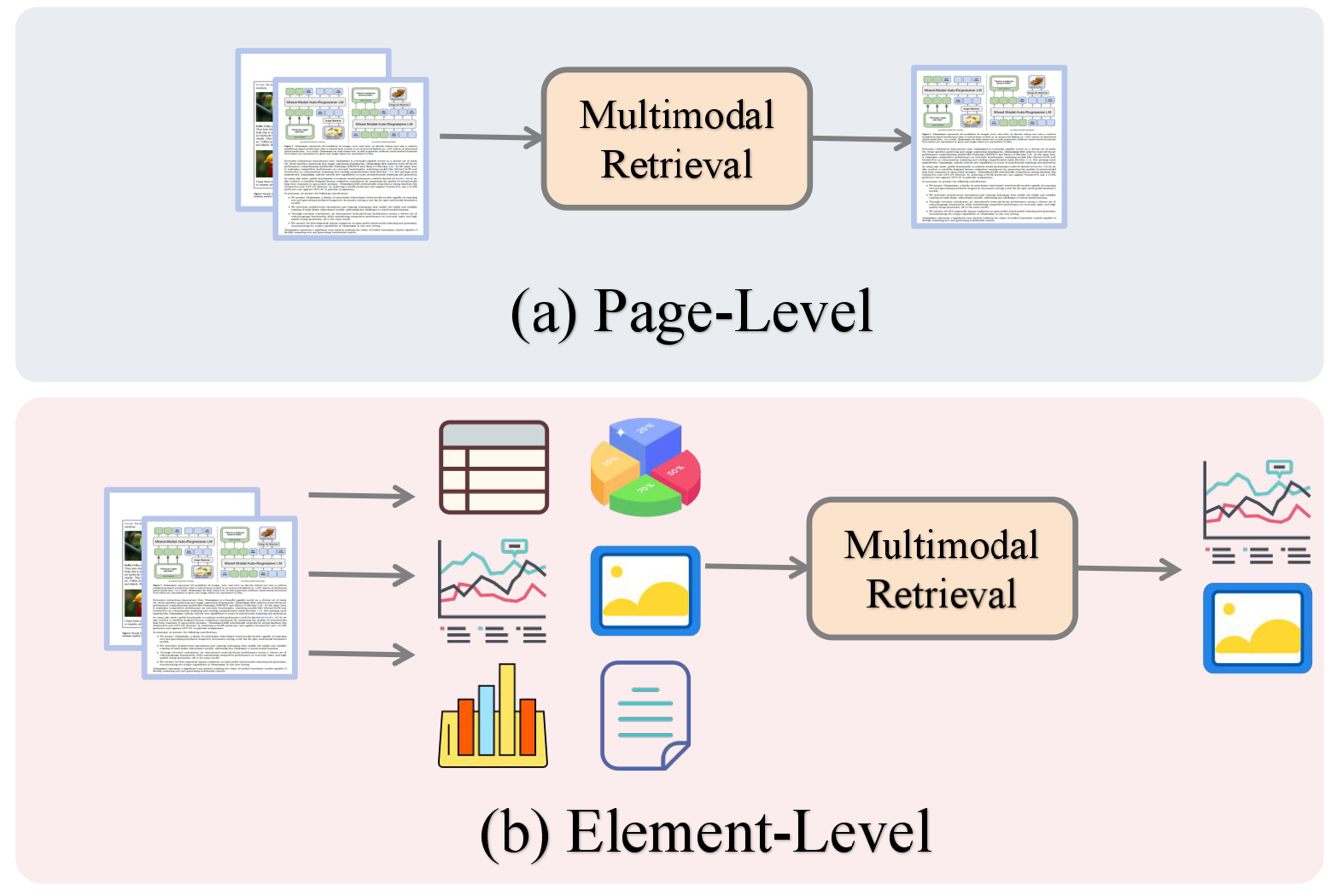
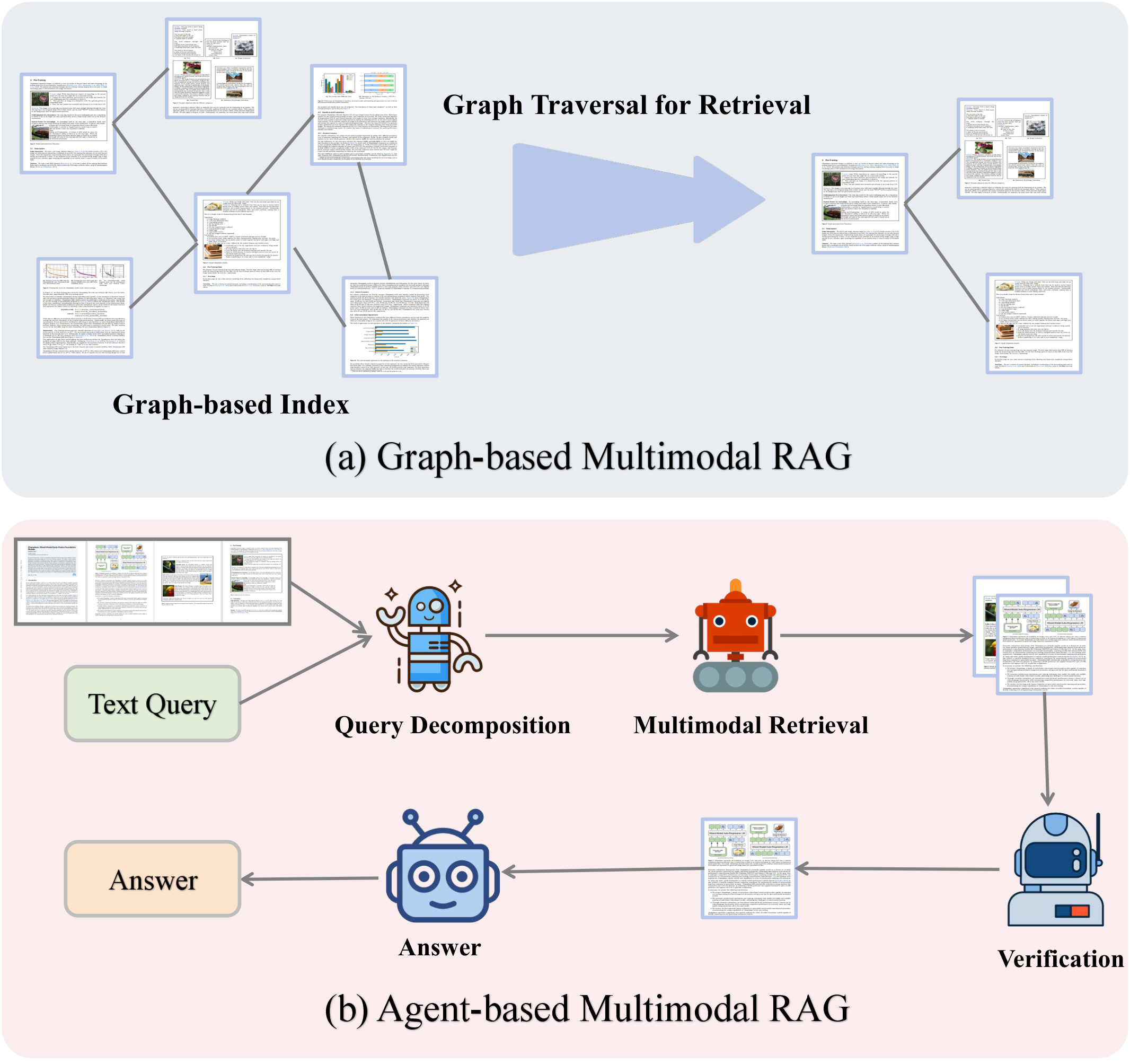
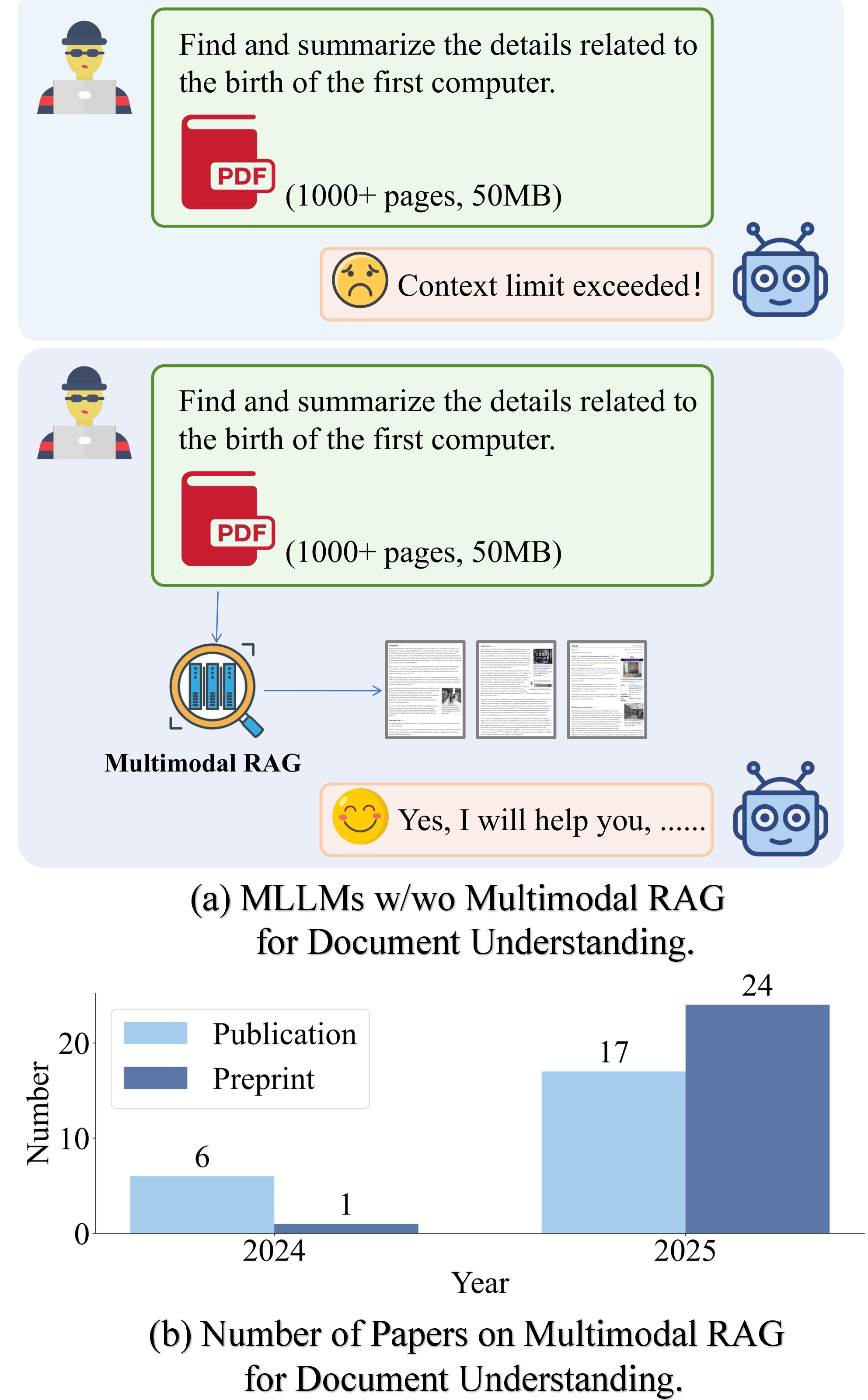
Large documents — 1000+ pages of interleaved text, tables, and charts — overwhelm a model's context window. Multimodal RAG retrieves only the evidence that matters, enabling reasoning that native MLLMs cannot reach alone.
(a) MLLMs with vs. without Multimodal RAG for large-document comprehension. (b) Explosive growth in related publications from 2024 to 2025.
0
Papers in 2025
0
Growth vs. 2024